BUILD TARGET
내 PC에 Hadoop 실습 환경을 만든다
VirtualBox와 Ubuntu 20.04 LTS 위에서 Java 15, Hadoop 3.2.1 환경을 직접 구성하며 설치 흐름을 따라갑니다.
빅데이터를 개념으로만 넘기지 말고, Ubuntu 가상머신 위에 Hadoop 3.2.1을 올려 HDFS와 MapReduce 흐름을 직접 확인하세요. 분산 저장과 처리 구조를 명령어와 WordCount 실습으로 연결하는 초급 데이터 엔지니어링 강의입니다.

빅데이터 하둡 직접 설치 인프런 강의
PUBLIC SIGNAL
582명이 선택한 하둡 입문 경로
공개 데이터 기준 수강생 582명, 좋아요 795개, 평점 4.5를 기록한 인프런 베스트 하둡 강의입니다.
인프런 베스트 강의 · 평점 4.5 · 수강평 43개
85개
수업 · 총 6시간 39분 구성
VirtualBox, Ubuntu 20.04 LTS, Java 15, Hadoop 3.2.1 실습
HDFS Shell Commands부터 YARN, MapReduce까지 순차 학습
BUILD TARGET
VirtualBox와 Ubuntu 20.04 LTS 위에서 Java 15, Hadoop 3.2.1 환경을 직접 구성하며 설치 흐름을 따라갑니다.
COMMAND FLOW
파일 업로드, 조회, 삭제 같은 HDFS Shell Commands를 통해 NameNode와 DataNode 기반 저장 흐름을 눈으로 확인합니다.
PROCESSING MODEL
Mapper, Reducer, Shuffle, Sort 개념을 Python과 Java 예제로 따라가며 분산 처리 모델을 비교합니다.
COURSE SCALE
Big Data 개념, Hadoop Stack, HDFS, YARN, MapReduce, 구현 실습까지 85개 수업으로 단계별 구성되어 있습니다.
Visual Proof
강의 커버와 참고 이미지를 바탕으로, 오늘 선택한 디자인 톤에 맞춘 광고용 화면 흐름을 보여줍니다.
강의가 단순 설치에서 끝나지 않고 Big Data 개념, Hadoop Stack, HDFS, YARN, MapReduce로 확장되는 학습 경로를 보여줍니다.

NameNode, DataNode, Replica 같은 용어를 외우는 대신 HDFS 명령어와 구조 보드를 함께 보며 분산 저장 방식을 연결합니다.

WordCount 예제로 입력 데이터가 Mapper, Shuffle, Sort, Reducer를 거쳐 결과로 바뀌는 과정을 확인합니다.

수강 전 VirtualBox, Ubuntu, Java, Hadoop 버전 등 필요한 환경을 미리 점검할 수 있어 설치형 강의 선택 리스크를 줄입니다.

하둡을 설치해 본 경험은 HDFS, YARN, MapReduce가 왜 데이터 엔지니어링의 기초 시스템으로 언급되는지 이해하는 발판이 됩니다.
PROBLEM
HDFS, YARN, MapReduce는 이름만 보면 각각의 역할이 분리되어 보입니다. 하지만 실제로는 저장, 자원 관리, 처리 실행이 한 흐름 안에서 맞물립니다.
그래서 하둡 입문에서 가장 위험한 순간은 개념을 외웠다고 착각하는 때입니다. 설치하지 않으면 설정 파일, 데몬 실행, 파일 시스템 명령어, 처리 결과가 어떤 순서로 연결되는지 감이 잘 남지 않습니다.
이 강의는 하둡을 멋진 용어로 포장하기보다, 내 PC 위에 실습 환경을 만들고 직접 확인하는 방식으로 빅데이터 하둡의 구조를 잡습니다.

OUTCOME
이 강의의 핵심 산출물은 ‘하둡을 들어봤다’가 아닙니다. Ubuntu 가상머신 위에 Hadoop 3.2.1 환경을 구성하고, HDFS 명령어를 실행하고, WordCount 예제로 처리 모델을 따라간 경험입니다.
분산 저장은 NameNode와 DataNode 개념으로, 분산 처리는 Mapper와 Reducer 흐름으로 나뉘어 정리됩니다. 학습자는 각 용어를 정의로만 기억하는 대신 명령어와 결과 화면을 통해 다시 떠올릴 수 있습니다.
Decision Point
커리큘럼과 미리보기를 바로 확인하세요
랜딩은 강의의 핵심 판단 기준만 압축합니다. 가격, 섹션별 수업, 수강평, 미리보기는 인프런 상세 페이지에서 최종 확인하는 흐름이 가장 정확합니다.
WORKFLOW
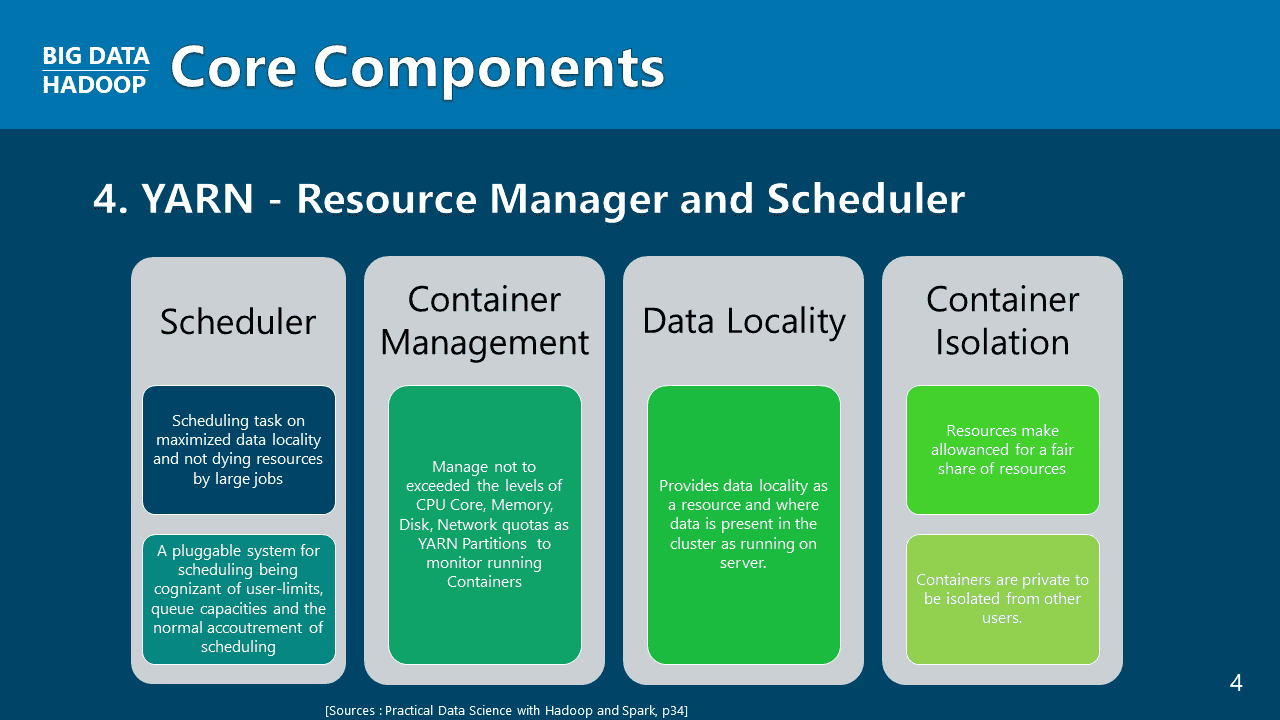
학습 흐름은 Big Data의 배경에서 시작합니다. 왜 하둡이 등장했는지, Hadoop Stack 안에서 HDFS와 YARN, MapReduce가 어떤 위치를 갖는지 먼저 잡습니다.
그 다음 설치로 내려갑니다. 가상머신, Ubuntu, Java, Hadoop 설치를 거쳐 실제 하둡 환경을 구성합니다. 이후 HDFS Shell Commands와 Hadoop Common Commands를 사용해 파일 시스템을 다룹니다.
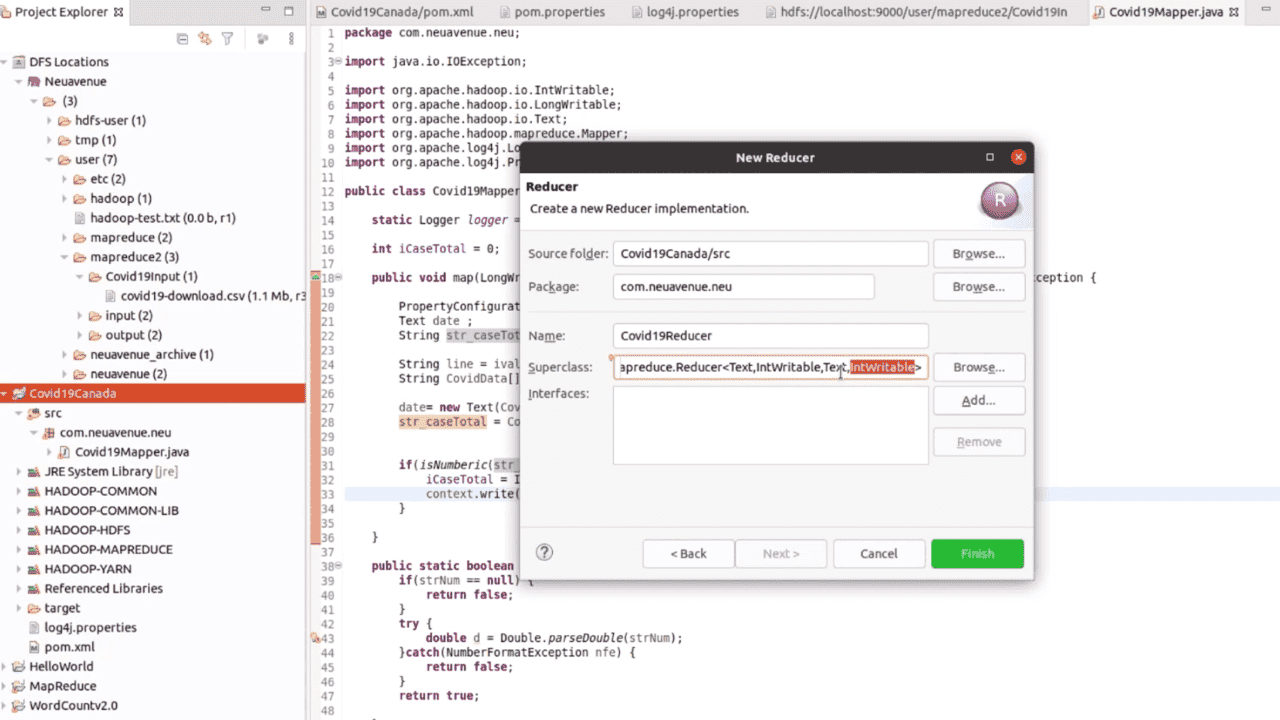
마지막으로 MapReduce WordCount를 실행합니다. Python으로 Mapper와 Reducer를 구현해 보고, Java MapReduce 환경 세팅과 구현 흐름까지 확인하면서 처리 모델을 비교합니다.
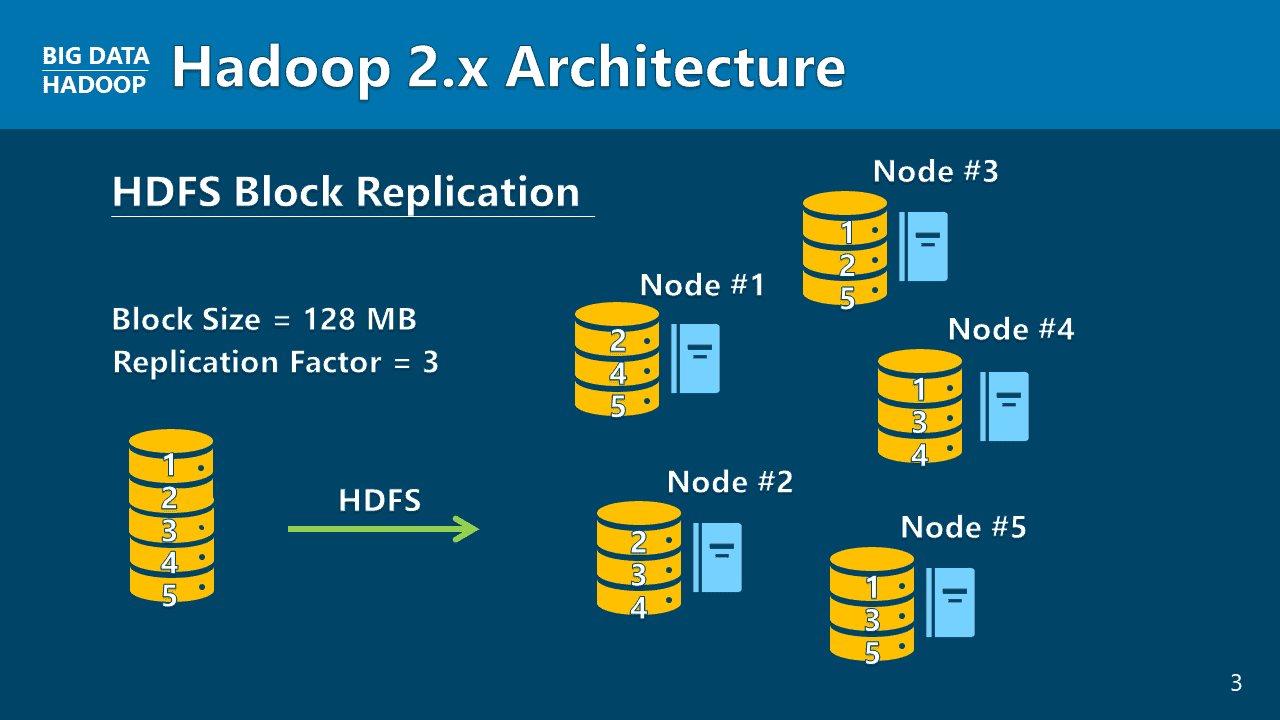
HDFS SYSTEM
HDFS는 하둡의 핵심이지만, 처음 배우는 사람에게는 추상적인 파일 시스템처럼 느껴질 수 있습니다. 이 강의는 NameNode, DataNode, Rack, Replica, High Availability, Federation 같은 개념을 분산 저장 구조 안에서 정리합니다.
여기에 HDFS Shell Commands를 붙이면 구조가 더 선명해집니다. 파일을 올리고 확인하고 다루는 과정에서 ‘하둡이 데이터를 어떻게 나누고 관리하는가’를 직접 확인하게 됩니다.

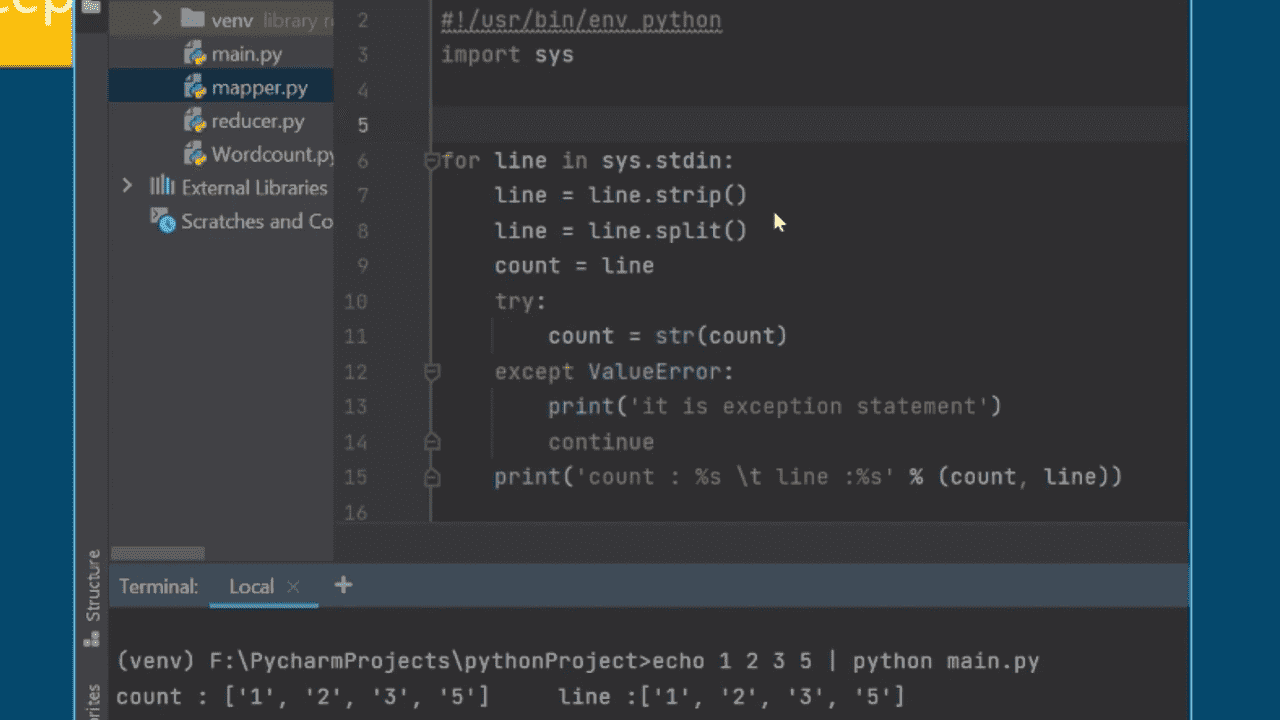
MAPREDUCE SEQUENCE
MapReduce는 개념만 보면 단순해 보이지만, 실제로는 입력 분할, Map 단계, Shuffle, Sort, Reduce 단계가 순서대로 이어집니다. 이 흐름을 가장 작게 확인하기 좋은 예제가 WordCount입니다.
강의에서는 Python과 Java 예제를 통해 같은 처리 모델을 다른 구현 방식으로 바라봅니다. 덕분에 MapReduce 강의를 처음 접하는 학습자도 Mapper와 Reducer가 어떤 책임을 갖는지 비교하며 이해할 수 있습니다.
PROOF
이 강의는 공개 데이터 기준 수강생 582명, 좋아요 795개, 수강평 43개, 평점 4.5를 기록한 인프런 베스트 강의입니다. 또한 2026년 5월 15일 업데이트 정보가 확인됩니다.
85개 수업과 약 6시간 39분 구성은 하둡 입문자가 하루에 끝내기보다, 개념과 실습을 나누어 따라가기 좋은 밀도입니다. 미리보기 수업도 제공되므로 구매 전 강의 톤과 실습 방식을 확인할 수 있습니다.

DECISION
현재 공개 정보 기준 가격은 55,000원입니다. 다만 최신 가격, 수강 가능 여부, 실습 환경, 커리큘럼 구성은 인프런 강의 상세 페이지에서 확인하는 것이 가장 정확합니다.
이 강의는 하둡 전문가가 되는 것을 약속하는 과정이 아닙니다. 대신 빅데이터 하둡을 처음 배우는 사람이 분산 저장과 분산 처리 구조를 직접 설치하고 명령어와 코드로 확인하도록 돕는 입문 실습 과정입니다.
Hadoop 강의를 찾고 있다면, 먼저 미리보기와 환경 조건을 확인해 보세요. 내 PC에서 설치 실습을 따라갈 수 있다면 학습 효과가 훨씬 선명해집니다.
FAQ
네. 강의 레벨은 초급이며 Big Data 개념, Hadoop 탄생 배경, Hadoop Stack부터 시작합니다. 다만 설치와 명령어 실습이 포함되어 있어 기본적인 PC 사용, 가상머신 설치, Linux CLI에 대한 거부감이 적을수록 따라가기 좋습니다.
공개 정보 기준 VirtualBox, Ubuntu 20.04 LTS, Java 15, Hadoop 3.2.1 기반 실습을 안내합니다. 실제 수강 전에는 인프런 상세 페이지에서 최신 환경, 버전, 준비물을 확인하는 것이 좋습니다.
강의에는 Python 언어로 Mapper와 Reducer를 구현하는 흐름이 포함되어 있습니다. 또한 Java 기반 MapReduce 환경 세팅과 구현도 다루므로, Java 기초가 있으면 전체 처리 모델을 더 넓게 비교할 수 있습니다.
아니요. 이 강의는 취업, 이직, 연봉, 전문가 수준을 보장하지 않습니다. 목표는 하둡을 직접 설치하고 HDFS, YARN, MapReduce 흐름을 실습으로 확인해 데이터 엔지니어링 입문 기반을 만드는 것입니다.
현재 공개 정보 기준 가격은 55,000원이지만, 최신 가격, 할인 여부, 수강 가능 여부, 커리큘럼 업데이트는 인프런 강의 상세 페이지에서 확인해야 합니다. CTA를 통해 인프런에서 미리보기와 상세 정보를 확인할 수 있습니다.
하둡 관련 문서나 데이터 엔지니어링 자료를 볼 때 HDFS, NameNode, DataNode, YARN, MapReduce, WordCount 같은 용어를 실제 실행 흐름과 연결해 이해하는 데 도움이 됩니다. 이후 Spark, Hive 등 다른 빅데이터 도구를 학습할 때도 기초 구조를 잡는 발판이 됩니다.
Course CTA
가격, 커리큘럼, 수강평, 미리보기는 인프런 상세 페이지에서 최종 확인하세요. 광고용 링크는 항상 강의 상세로 연결됩니다.
https://www.ludgi.ai/landing/inflearn-ad-hadoop-bigdata-installation-spacex-20260531-111214-1dd52d7d
럿지 담당자와의 대화